Итак, задача − представить текстовую информацию в компьютере. Т.к. текстовая информация по своей природе дискретна, нет необходимости предварительно её преобразовывать.
Сколько разрядов (бит) надо взять, чтобы закодировать
заданное количество символов? Напомним, что количество различных последовательностей
из нулей и единиц, которые можно записать в n двоичных разрядах, равна К=
![]() (мощность алфавита).
(мощность алфавита).
Если n = 4, мощность алфавита K = ![]() =
16;
=
16;
Если n = 5, мощность алфавита K = ![]() = 32.
= 32.
Какое количество разрядов требуется, чтобы закодировать буквы русского алфавита? В алфавите 33 буквы, т.е. 5-ти разрядов уже не хватает. Реально же требуется около 200 различных символов (большие и маленькие буквы, причём как минимум двух алфавитов – русского и английского, цифры, знаки препинания, скобки-кавычки и т.д.). Минимальная подходящая длина равна 8:
n = 8, K = ![]() =
256.
=
256.
Видимо, именно поэтому и получилась устоявшаяся длина байта (один байт − один символ).
Символы алфавита закодировали следующим образом:
- составили квадратную таблицу размера 16 х 16;
- пронумеровали строки и столбцы числами от 0000 до 1111 в двоичной с.с., либо в щестнадцатеричной числами от 0 до F;
- записали в таблицу по определённому алгоритму все используемые символы.
Код символа составляется из номера строки (старшие разряды) и номера столбца (младшие разряды), на пересечении которых этот символ находится. А десятичный код символа получается, если эту последовательность перевести из шестнадцатеричной (или двоичной) с.с. в десятичную.
Однако во время создания большинства операционных систем никто не позаботился предусмотреть возможность представления информации на языках, отличных от английского. Наиболее популярной кодировкой была (и фактически ей и остается) ASCII (American Standard Code for Information Interchange – Американский Стандартный Код для Информационного Обмена). Таблица строго определяет ровно половину возможных символов (латинские буквы, арабские цифры, знаки препинания, управляющие символы). Они имеют десятичные коды от 0 до 127.
Стандарт ASCII с 8 битами не определяет содержание «нижней» половины таблицы кодировки. Поэтому МЕЖДУНАРОДНАЯ ОРГАНИЗАЦИЯ ПО СТАНДАРТИЗАЦИИ (ISO) взяла ответственность по определению семейства стандартов, известных как ISO 8859-X семейство. Это семейство есть совокупность 8-ми битных кодировок, где младшая половина каждой кодировки (символы с кодами 0-127) соответствует ASCII, а старшая половина определяет символы для различных языков. Например, следующие кодовые страницы определены для:
- 8859-0 - Новый европейский стандарт (так называемый Latin 0)
- 8859-1 - Европа, Латинская Америка (также известный как Latin 1)
- 8859-2 - Восточная Европа
- 8859-5 - Кириллица
- 8859-8 - Идиш
В Latin 1 старшая половина таблицы определяет различные символы, которые не являются частью английского алфавита, но присутствует в различных европейских языках (немецкие umlauts, французские диакритические знаки и т.д).
Русские буквы в кодировке ISO 8859-5 расположены в алфавитном порядке. Коды с 176 по 207 - заглавные буквы, коды с 208 по 239 - строчные буквы. Остальные cимволы кириллицы, включая русскую букву "Ё", располагаются на местах 161 - 175 (заглавные буквы) и 241 - 255 (строчные буквы).
Но поскольку (как это часто случается со стандартами) этот стандарт был разработан без принятия во внимание реальных процессов, проходящих в СССР (когда это еще было), то единственное, что было действительно достигнуто с введением этого стандарта, так это только увеличение беспорядка с кодировками кириллицы. Дело в том, что для русских букв существуют по крайней мере 3 различных кодировки, связанные с различными операционными системами.
Во-первых, это кодировка CP-866 (Code Page — кодовая страница). Здесь все специфические европейские символы были заменены на кириллицу, оставляя псевдографические символы нетронутыми. Следовательно, это не портило вид программ, использующих для работы текстовые окна, а также обеспечило символы кириллицы в них. Этот стандарт все еще жив и чрезвычайно популярен в среде МС-ДОС (система МС-ДОС тоже жива). Именно в этой ОС работает оболочка Турбо Паскаль (Таблица 1).
| Вторая шестнадцатеричная цифра кода | |||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
| Первая цифра кода | 0 | У | п | р | а | в | л | я | ю | щ | и | е | |||||
| 1 | с | и | м | в | о | л | ы | ||||||||||
| 2 | ! | " | # | $ | % | & | ‘ | ( | ) | * | + | , | - | . | / | ||
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? | |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ^ | _ | ` | |
| 6 | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | ||
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | ||
| 8 | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П | |
| 9 | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я | |
| A | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п | |
| B | С | и | м | в | о | л | ы | ||||||||||
| C | п | с | е | в | д | о- | |||||||||||
| D | г | р | а | ф | и | к | и | ||||||||||
| E | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я | |
| F | Ё | ё | |||||||||||||||
Рассмотрим таблицу подробнее.
Первые 32 места (первые две строки с номерами 0 и 1) отданы производителям аппаратных средств. В этой области размещены так называемые управляющие коды, которым не соответствуют никакие символы.
В строке с номером 3 в столбцах с нулевого по девятый идут цифры. Они расположены таким образом для того, чтобы их коды так же шли подряд. Найдём шестнадцатиричные, двоичные и десятичные коды цифр:
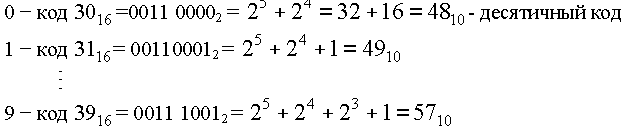
Со строки с номером 4 начинаются буквы английского алфавита.
Например,
‘А’ имеет код ![]()
‘а’ имеет код ![]()
(т.е. разница между большими и соответствующими маленькими буквами равна 32).
Вообще, отличительным признаком заглавных латинских букв является ноль в 5-ом бите, тогда как у строчных там стоит 1.
Во-вторых, в Советском Союзе тоже были разработаны свои таблицы, например КОИ-7 (код обмена информацией, семизначный). Затем был разработан КОИ-8 - его происхождение относится к временам СЭВ государств Восточной Европы. Он был разработан довольно давно для UNIX машин. Так как, говоря о UNIX, мы подразумеваем сеть, то основной идей при создании KOI-8 стандарта была идея об обеспечении перемещения кириллической информации по сети.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| A | ё | |||||||||||||||
| B | Ё | |||||||||||||||
| C | ю | а | б | ц | д | е | ф | г | х | и | й | к | л | м | н | о |
| D | п | я | р | с | т | у | ж | в | ь | ы | з | ш | э | щ | ч | ъ |
| E | Ю | А | Б | Ц | Д | Е | Ф | Г | Х | И | Й | К | Л | М | Н | О |
| F | П | Я | Р | С | Т | У | Ж | В | Ь | Ы | З | Ш | Э | Щ | Ч | Ъ |
Разработчики KOI-8 применили очень продуманный подход. Они поместили символы русской кириллицы в «нижней» части расширенной ASCII таблицы таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы. Это означает, что, если в тексте, написанном в KOI-8, убирать восьмой бит каждого символа, то мы все еще имеем "читабельный" текст, хотя он и написан английскими символами! Сегодня КОИ-8 имеет распространение в компьютерных сетях на территории России и в российском секторе Интернета (эта же кодировка - ОС UNIX).
Следует отметить, что KOI8-R подходит только для русских текстов, и как следствие был создан украинский вариант KOI-8: KOI8-U.
В-третьих, кодировка, известная как CP-1251, была введена “извне” компанией Microsoft, но глубоко закрепилась в связи с широким распространением программных продуктов этой фирмы. Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| A | Ё | |||||||||||||||
| B | ё | |||||||||||||||
| C | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| D | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
| E | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| F | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
Кроме того, в операционной системе MS-DOS могут действовать ещё две кодировки (ГОСТ и ГОСТ-альтернативная).
В результате слово “ёрш” в кодировке DOS (CP-866) имеет вид: F1-E0-E816. Эта последовательность кодов под Windows (кодировка CP-1251) будет декодирована как “саи”, а в ОС UNIX ( КОИ-8) − как “яюх”.
Чтобы избежать подобных проблем предлагается в качестве
стандарта использовать не однобайтную кодировку, а двухбайтную. Это означает,
что один байт будет содержать собственно код символа, а второй байт –
информацию о том, к какому языку принадлежит символ. Такая 2-х байтовая
кодировка позволяет обеспечить уникальные коды для ![]() различных символов. Но при этом все текстовые документы становятся
вдвое длиннее. Именно это и сдерживало долгое время переход на данную
систему, которая называется UNICODE. Зато текст в такой кодировке всегда
будет читаемым, независимо от языка и операционной системы.
различных символов. Но при этом все текстовые документы становятся
вдвое длиннее. Именно это и сдерживало долгое время переход на данную
систему, которая называется UNICODE. Зато текст в такой кодировке всегда
будет читаемым, независимо от языка и операционной системы.
В настоящее время распределено около 40 000 позиций из 65 535 возможных, и им соответственно присвоены стандартные имена. Эти позиции зарезервированы за буквами практически всех известных алфавитов, включая древнеегипетские иероглифы. Т.е., используя этот стандарт, можно писать одновременно на русском и греческом, делая вставки на японском, с использованием одного единственного шрифта.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами (т.е. первые 256 символов UNICODE = Latin-1= ISO 8859-1). Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены коды от U+0400 до U+052F.
В Юникоде для кириллицы выделено два раздела:
- Cyrillic (U+0400 — U+04FF)
- Cyrillic Supplement (U+0500 — U+052F).
Символы можно разделить на 3 группы:
- U+0400 — U+045F — это символы из ISO 8859-5, но перемещённые вверх на 864 позиции (36016).
- U+0460 — U+0489 — исторические буквы.
- U+048A — U+052F — это дополнительные буквы для разных языков, использующих кириллицу.
Вопросы и задачи для самопроверки
1. Какая последовательность десятичных кодов (номеров) будет соответствовать в кодировке ASCII словам
— file;
— help;
Какая последовательность кодов будет соответствовать этим словам в двоичном и шестнадцатиричном кодах?
2. Пользуясь таблицей ASCII расшифровать текст
— 57 69 6E 64 6F 77 73 2D 39 35
— 63 6F 6D 65 2D 4F 4E 2D 6C 69 6E 65